To all my loved ones, cheers ♥
Theme adapted from orderedlist
Emulating a Distributed Network on a Single Linux Host
28 Oct 2023 - Guanzhou Hu
Recently, I need to benchmark a lightweight distributed system codebase on a single host for my current research project. I want to have control over the network performance parameters (including delay, jitter distribution, rate, loss, etc.) and test a wide range of parameter values; meanwhile, I want to avoid pure software-based simulation. Thus, I opt in for using kernel-supported network emulation. In this post, I document what I tried and what finally worked.
This post assumes latest Linux kernel version and is tested on v6.5.7.
Problem Setting
I have a distributed system codebase consisting of the following processes, each of which should conceptually run on a separate physical machine:
- \(S\) server nodes,
- \(C\) client nodes,
- and one manager node.
W.L.O.G., let’s ignore the client nodes and only talk about the server nodes plus the manager. I would like to test a wide range of different network performance parameters on the network connections between servers. Doing that across real physical machines would be prohibitively resource-demanding (as it requires a bunch of powerful machines all connected with each other through physically links that are as strong as the “best parameters” you will test against). Processes in my codebase are not computation- or memory-demanding, though; so it might be a good idea to run them on a single host and emulate a network environment among them.
There’re not really any canonical tutorials online demonstrating how to do this. After a bit of searching & digging, I found Linux kernel-supported network emulation features to be quite promising.
First Try: tc netem on LoopBack
The first tool to introduce here is the netem queueing discipline (qdisc) 1 provided by the tc traffic control command. Each network interface in Linux can have an associated software queueing discipline that sits atop the device driver queue. netem is one of them and it provides functionality for emulating various network properties, including delay, jitter distribution, rate, loss, corruption, duplication, and reordering, etc.
For example, we can put a netem qdisc on the loopback interface that injects a 100ms delay with a Pareto-distributed jitter around 10ms and limits the rate as 1Gbps:
~$ sudo tc qdisc add dev lo root netem delay 100ms 10ms distribution pareto rate 1gibit
~$ ping localhost
PING localhost (127.0.0.1) 56(84) bytes of data.
64 bytes from localhost (127.0.0.1): icmp_seq=2 ttl=64 time=192 ms
64 bytes from localhost (127.0.0.1): icmp_seq=4 ttl=64 time=226 ms
64 bytes from localhost (127.0.0.1): icmp_seq=5 ttl=64 time=193 ms
...
It feels natural to just put a netem qdisc on the loopback interface, let all processes bind to a different port on localhost, and let them talk to each other all through loopback. It seemed to work pretty well until I found two significant caveats:
- Since all process transfer packets through the same loopback interface, packets with different source-destination pairs will all be congesting with each other in the same queue, creating unwanted interference and often overflowing the loopback queue.
- Only one
netemqdisc is allowed on each interface. This means we cannot emulate different parameters for different links among different pairs of processes.
What we need are separate network interfaces for the processes.
Didn’t Work: dummy Interfaces
The dummy kernel module supports creating dummy network interfaces that route packets to the host itself. However, creating a netem qdisc on a dummy interface doesn’t really work 2 3.
~$ sudo ip link add dummy0 type dummy
~$ sudo ip addr add 192.168.77.0/24 dev dummy0
~$ sudo ip link set dummy0 up
~$ sudo tc qdisc add dev dummy0 root netem delay 10ms
~$ sudo tc qdisc show
...
qdisc netem 80f8: dev dummy0 root refcnt 2 limit 1000 delay 10ms
Though the qdisc is indeed listed, pinging the associated address still shows lightning-fast delay:
~$ ping 192.168.77.0
PING 192.168.77.0 (192.168.77.0) 56(84) bytes of data.
64 bytes from 192.168.77.0: icmp_seq=1 ttl=64 time=0.019 ms
64 bytes from 192.168.77.0: icmp_seq=2 ttl=64 time=0.024 ms
64 bytes from 192.168.77.0: icmp_seq=3 ttl=64 time=0.024 ms
...
This is because the dummy interface is just a “wrapper”; it is still supported by the loopback interface behind the scene. We can verify this fact using:
~$ sudo ip route get 192.168.77.0
local 192.168.77.0 dev lo src 192.168.77.0 uid 0
cache <local>
Notice it is reported that the route is backed by dev lo. In fact, if a netem qdisc is still being applied to loopback as of previous section, you will see that delay when pinging dummy0. Dummy is not we are looking for here.
Solution: Network Namespaces & veths
What we are actually looking for are network namespaces and veth-type interfaces 4 5. In Linux, a network namespace is an isolated network stack that processes can attach to. By default, all devices are in a nameless namespace. One can create named namespaces using ip netns commands and assign them to running processes (or launch new processes directly from them through ip netns exec). Namespaces are a perfectly tool for our task here.
To give connectivity between namespaces without bringing in physical devices, one can create veth (virtual Ethernet) interfaces. By design, veth interfaces come as pairs: you must create pairs of two veths at the same time. This post 6 gives a nice demonstration of creating two namespaces and making a pair of veths to connect them.
However, this is not enough for us, because we would want more than 2 isolated devices, each being able to talk to everyone else. To achieve this, we make use of a bridge device. We create one pair of veths per namespace, put one end into the namespace while keeping the other end, and then bridge those ends together. All namespaces can then find a route to each other through the bridge; also, the bridge can talk to each of the namespaces. Since we have a manager process, it is quite natural to let the manager use the bridge device and let each server process reside in its own namespace and use the veth device put into it.
Let’s walk through this step-by-step for a 3-servers setting.
-
Create namespaces and assign them proper IDs:
~$ sudo ip netns add ns0 ~$ sudo ip netns set ns0 0 ~$ sudo ip netns add ns1 ~$ sudo ip netns set ns1 1 ~$ sudo ip netns add ns2 ~$ sudo ip netns set ns2 2 -
Create a bridge device
brgmand assign address10.0.1.0to it:~$ sudo ip link add brgm type bridge ~$ sudo ip addr add "10.0.1.0/16" dev brgm ~$ sudo ip link set brgm up -
Create
vethpairs (vethsX-vethsXm) for servers, put thevethsXend into its corresponding namespace, and assign address10.0.0.Xto it:~$ sudo ip link add veths0 type veth peer name veths0m ~$ sudo ip link set veths0 netns ns0 ~$ sudo ip netns exec ns0 ip addr add "10.0.0.0/16" dev veths0 ~$ sudo ip netns exec ns0 ip link set veths0 up # repeat for servers 1 and 2 -
Put the
vethsXmend under the bridge device:~$ sudo ip link set veths0m up ~$ sudo ip link set veths0m master brgm # repeat for servers 1 and 2
This gives us a topology that looks like the following figure:
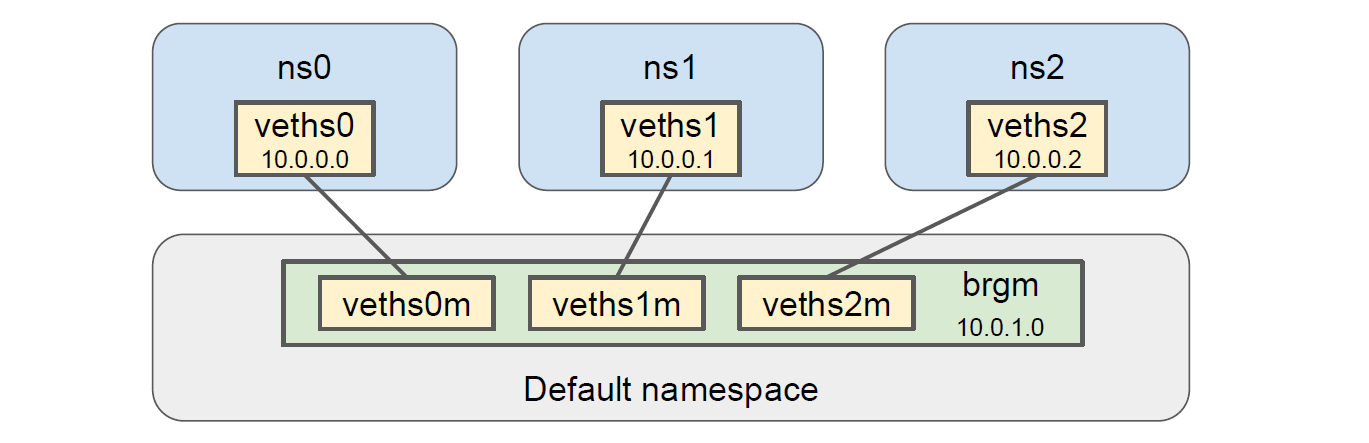
Let’s do a bit of delay injection with netem to verify that this topology truly gives us what we want. Say we add 10ms delay to veths1 and 20ms delay to veths2:
~$ sudo ip netns exec ns1 tc qdisc add dev veths1 root netem delay 10ms
~$ sudo ip netns exec ns2 tc qdisc add dev veths2 root netem delay 20ms
Pinging the manager from server 1:
~$ sudo ip netns exec ns1 ping 10.0.1.0
PING 10.0.1.0 (10.0.1.0) 56(84) bytes of data.
64 bytes from 10.0.1.0: icmp_seq=1 ttl=64 time=10.1 ms
64 bytes from 10.0.1.0: icmp_seq=2 ttl=64 time=10.1 ms
64 bytes from 10.0.1.0: icmp_seq=3 ttl=64 time=10.1 ms
...
Pinging server 2 from server 1:
~$ sudo ip netns exec ns1 ping 10.0.0.2
PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
64 bytes from 10.0.0.2: icmp_seq=1 ttl=64 time=30.1 ms
64 bytes from 10.0.0.2: icmp_seq=2 ttl=64 time=30.1 ms
64 bytes from 10.0.0.2: icmp_seq=3 ttl=64 time=30.1 ms
...
All good!
There are also obvious ways to extend this topology to allow even more flexibility; for example, each server’s could own multiple devices in its namespace that have different connectivity and different performance parameters, etc. Let me describe one example extension below.
Extension: Symmetric Ingress Emulation w/ ifbs
It is important to note that most of netem’s emulation functionality applies only to the egress side of the interface. This means all the injected delay happen on the sender side for every packet. In some cases, you might want to put custom performance emulation on the ingress side of the servers’ interfaces as well. To do so, we could utilize the special IFB devices 7.
First, load the kernel module that implements IFB devices:
~$ sudo modprobe ifb
By default, two devices ifb0 and ifb1 are added automatically. You can add more by doing:
~$ sudo ip link add ifb2 type ifb
We then bring one IFB device to each server’s namespace and redirect all the incoming traffic to the veth interface to go through the ifb device’s egress queue first. This is done by adding a special ingress qdisc to the veth (which can exist simultaneously with an egress netem qdisc we added earlier) and placing a filter rule to simply “move” all ingress packets to the ifb interface’s egress queue. The ifb device will automatically move the packet back after it has gone through the ifb’s egress queue.
~$ sudo ip link set ifb0 netns ns0
~$ sudo ip netns exec ns0 tc qdisc add dev veths0 ingress
~$ sudo ip netns exec ns0 tc filter add dev veths0 parent ffff: protocol all u32 match u32 0 0 flowid 1:1 action mirred egress redirect dev ifb0
~$ sudo ip netns exec ns0 ip link set ifb0 up
We can then put a netem qdisc on the ifb interface, which effectively emulates specified performance on the ingress of the veth. For example:
~$ sudo ip netns exec ns0 tc qdisc add dev ifb0 root netem delay 5ms rate 1gibit
Summary
To achieve our goal of emulating network links among distributed processes, on a single host, beyond the limitation of a single loopback interface, we can take the following steps:
- Create separate network namespaces, probably one for each process, using
ip netns. - Create
vethinterface pairs, probably one pair for each process, usingip link ... type veth. - Put one end of each
vethpair into the corresponding namespace, then keep the other ends and create a bridge that stitches them together. - Use
tc qdisc ... netemto apply thenetemqueueing discipline with desired parameters on thevethdevices for each process. - Run the processes with their corresponding network namespace attached.
Below is a script for setting up the above described topology for a given number of server processes:
#! /bin/bash
NUM_SERVERS=$1
echo
echo "Deleting existing namespaces & veths..."
sudo ip -all netns delete
sudo ip link delete brgm
for v in $(ip a | grep veth | cut -d' ' -f 2 | rev | cut -c2- | rev | cut -d '@' -f 1)
do
sudo ip link delete $v
done
echo
echo "Adding namespaces for servers..."
for (( s = 0; s < $NUM_SERVERS; s++ ))
do
sudo ip netns add ns$s
sudo ip netns set ns$s $s
done
echo
echo "Loading ifb module & creating ifb devices..."
sudo rmmod ifb
sudo modprobe ifb # by default, add ifb0 & ifb1 automatically
for (( s = 2; s < $NUM_SERVERS; s++ ))
do
sudo ip link add ifb$s type ifb
done
echo
echo "Creating bridge device for manager..."
sudo ip link add brgm type bridge
sudo ip addr add "10.0.1.0/16" dev brgm
sudo ip link set brgm up
echo
echo "Creating & assigning veths for servers..."
for (( s = 0; s < $NUM_SERVERS; s++ ))
do
sudo ip link add veths$s type veth peer name veths${s}m
sudo ip link set veths${s}m up
sudo ip link set veths${s}m master brgm
sudo ip link set veths$s netns ns$s
sudo ip netns exec ns$s ip addr add "10.0.0.$s/16" dev veths$s
sudo ip netns exec ns$s ip link set veths$s up
done
echo
echo "Redirecting veth ingress to ifb..."
for (( s = 0; s < $NUM_SERVERS; s++ ))
do
sudo ip link set ifb$s netns ns$s
sudo ip netns exec ns$s tc qdisc add dev veths$s ingress
sudo ip netns exec ns$s tc filter add dev veths$s parent ffff: protocol all u32 match u32 0 0 flowid 1:1 action mirred egress redirect dev ifb$s
sudo ip netns exec ns$s ip link set ifb$s up
done
echo
echo "Listing devices in default namespace:"
sudo ip link show
echo
echo "Listing all named namespaces:"
sudo ip netns list
for (( s = 0; s < $NUM_SERVERS; s++ ))
do
echo
echo "Listing devices in namespace ns$s:"
sudo ip netns exec ns$s ip link show
done
References
-
https://superuser.com/questions/764986/howto-setup-a-veth-virtual-network ↩
-
https://medium.com/@mishu667/creating-two-network-namespaces-and-connect-them-with-virtual-ethernet-veth-devices-565f83af4c37#:~:text=Network%20namespaces%20provide%20a%20powerful,control%20network%20connectivity%20between%20them. ↩
Comments welcome! 😉