To all my loved ones, cheers ♥
Theme adapted from orderedlist
Understanding Hierarchical Locking in Database Systems
06 Oct 2022 - Guanzhou Hu
Described in this classic paper by Jim Gray et. al, hierarchical locking has been a well-studied idea in database management systems (DBMS). Despite its long history, I found the theoretical notion of lock modes less intuitive and hard to understand upon first encounter. This post tries to distill the core motivations of hierarchical locking, break its design down into three pieces, and describe them progressively, to hopefully clarify this beautiful idea.
Traditional Locking
Consider a database with only one small table (i.e. relation), shared by multiple clients. The clients could issue concurrent transactions that read some tuples (i.e. records) of the table or update them with new values. To protect the database from data races, it is pretty natural to apply a traditional reader-writer lock on the table.
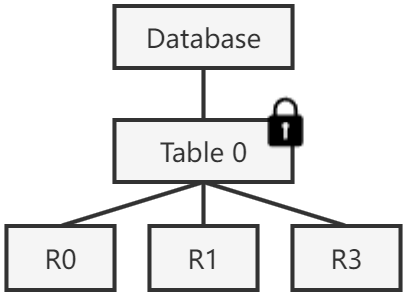
In database terminology, we denote acquiring a reader lock on the table as locking it in shared (S) mode, while acquiring a writer lock on the table as locking it in exclusive (X) mode. Multiple clients could hold S locks on the same table at the same time for reads. At most one client could hold an X lock on the table (with no S locks held by anyone else as well).
We call two locking attempts compatible if their lock modes are allowed to be held at the same time on the same thing. S mode is compatible with itself. S and X are not compatible with each other. X is of course also not compatible with itself.
Back to our problem scenario, since the database has only one table with a small number of tuples, a reasonable solution is to put a lock on that table. Read requests must attempt to acquire the lock in S mode and can proceed only after the acquirement is successful. Writes requests must attempt to acquire it in X mode. This is basically how a reader-writer lock works in classic systems. So far, so good.
Problem: what if the database is not in toy scale any more, but is composed of hundreds of tables, each having millions of records? Real-world databases can easily reach this scale. The traditional locking mechanism with uniform granularity puts a dilemma on choosing the granularity of locks:
-
Huge DB lock: we could choose to lock on coarse granularity, e.g., the entire database. However, it unacceptably hurts concurrency; a client transaction updating only one tuple in one table would block all other clients that try to read disjoint sets of tuples in the database.
-
One lock per tuple: alternatively, we could choose to put locks only at the finest granularity, in this case, tuples. A client transaction only locks the tuples it would touch in desired mode. This way, concurrency is preserved. The problem is that it forces large transactions to touch too many locks; e.g, a transaction that scans all tuples of a table will have to acquire potentially millions of locks. This can easily lead to prohibitive performance overhead.
Both choices are not ideal for overall performance. The solution to this problem is to introduce hierarchical locking on different levels of database resources.
Hierarchical Locking
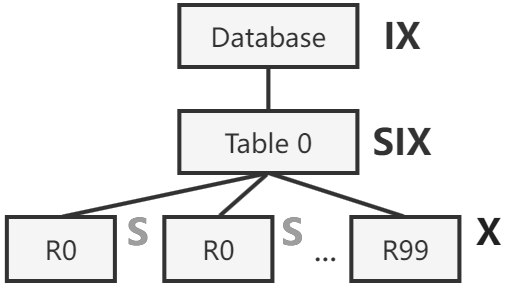
A database is naturally structured as a tree (or more generally, a DAG) of resources. For example, the following figure represents a database with 3 tables, each having 100 tuples. Tuples could further be decomposed into fields (i.e. attributes or columns); we consider tuples as the finest granularity in this post.
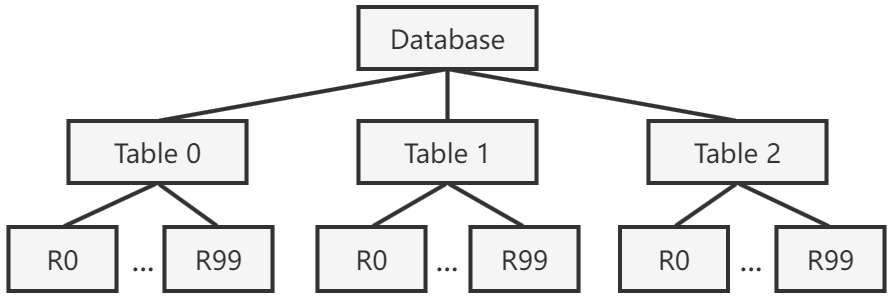
The core idea of hierarchical locking 1 2 is to allow putting locks on nodes of tree (which may be at different granularity levels), instead of only at a uniform granularity.
Version #1: Introduce Implicit Locking
In the first step towards hierarchical locking, we introduce implicit locking: locking an internal node in S mode implicitly locks all its descendant nodes with S mode; X mode behaves similarly.
- If a client wants to read or update only a few tuples, it better acquire
SorXlocks on the individual tuples. - If a client wants to scan or update most of the tuples of a table, it better acquire a single
SorXlock on the table – this implicitly grantsSorXpermissions on children nodes of the table, in this cases the tuples in it, to the client. - Compatibility between modes follow the same rules as in traditional locking.
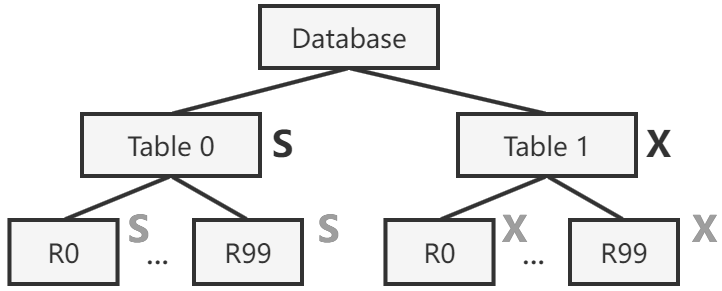
Implicit locking reduces the number of locks dramatically in cases of bulk operations, which nicely solves the performance problem of fine-grained locking. However, this mechanism itself is not enough, because it introduces correctness problems.
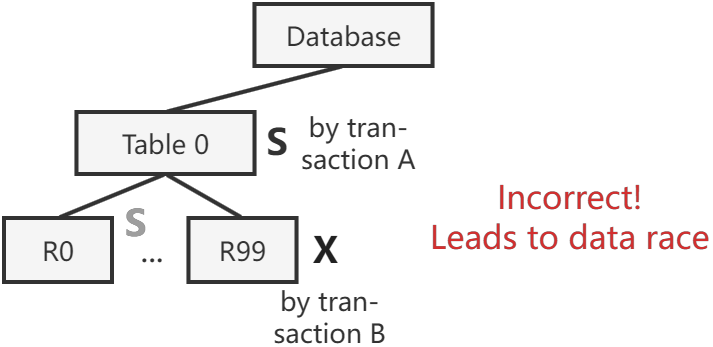
Problem: what about conflicting transactions that end up holding conflicting lock modes at different levels? Transaction B holds X locks on tuple R99 in table 0 and is going to update it. Transaction A comes and acquires a single S lock on table 0 to read all of its tuples. This situation should not be allowed. There are more incorrect scenarios besides this example.
Version #2: Introduce Intention Modes
To solve the correctness problem, we need to let internal nodes remember the locking state of its children. We introduce two intention lock modes: intention shared (IS) mode and intention exclusive (IX) mode.
To lock a node in X mode, the client must traverse the tree from root and lock all ancestor nodes along the path with IX mode, before locking the target node in X. Similarly, to lock a node in S mode, the client must traverse the tree from root and lock all ancestor nodes with IS mode, before locking the target node in S. By doing this, internal nodes now carry necessary information about the locking state of its descendant nodes in the subtree.
ISandSmodes are compatible: it is allowed to acquire aSlock on a node already locked inISmode – the two clients will probably share reading permissions of some children.ISandXmodes are not compatible: children of a node being updated by someone cannot be read by anyone else.IXandSmodes are not compatible: if a node and all its children are being read by someone, it is not allowed to grant any write permissions in this subtree to anyone else.IXandXmodes are obviously not compatible.ISmode is compatible with itself: multiple clients could be reading children of this node.IXmode is compatible with itself: multiple clients could be updating disjoint sets of children. Conflicts, if any, will be resolved at lower levels of the subtree.IXandISmodes are compatible: multiple clients could be reading and updating disjoint sets of children. Possible conflicts are again resolved at lower levels.
By always traversing the tree from root and locking ancestor nodes in intention modes (and releasing them in the reverse order when done), the correctness problem described in the previous section is now solved. Transaction B must have locked table 0 in IX already before it locks its R99 in X, which prevents transaction A from locking the entire table in S. If A and B touch different tables, however, they can proceed concurrently.

Problem: consider a workload that scans a big table while only attempting to update a few tuples in it. With the current version of hierarchical locking, it must either hold a big X lock on the table, or hold many S locks on tuples it reads. Can we further optimize performance for this situation?
Version #3: Introduce SIX Mode as an Optimization
We introduce a combined mode of S and IX to optimize for the aforementioned situation. The shared and intention exclusive (SIX) mode grants the client with read permission on all children, while optionally allowing it to further acquire X locks on some child nodes. This way, the client can hold a single SIX lock on the table plus a few X locks on tuples it is trying to modify.
SIXandISmodes are compatible: two clients can have disjoint sets of children nodes locked inXandSmodes, respectively. Conflicts, if any, will be resolved at those lower levels.SIXis not compatible with any mode other thanIS, including itself. Reasoning behind this is left as an exercise for the reader.
The original paper 1 presents a nice summary of compatibility between modes. Note that NL simply stands for null lock (i.e. not locked).

Related Issues
Concurrency control in database systems involve many more interesting issues besides hierarchical locking. To name a few examples:
- Semantic locking 3: we can have more lock purposes other than reads and writes. For example, increment operations can have its own semantic and be compatible with other concurrent increments. This allows us to manage locks with more compatibility modes.
- Deadlock solutions 4: deadlock detection by maintaining a dependency “wait-for” graph, or deadlock prevention (No-Wait, Wait-Die, Wound-Wait), etc.
- Two-phase locking (2PL) 5: within each transaction, locks must be acquired progressively in the acquiring phase and released in the finishing phase – once released, the transaction should not re-acquire a lock. This is a conservative protocol to prevent deadlocks and maintain serializability among transactions.
- Optimistic concurrency control (OCC) 6, consistency and durability, two-phase commit (2PC) 7, …
Some of these things have been covered in my past blog posts. Other techniques and their modern implications may be covered in my future blog posts.
References
Comments welcome! 😉