To all my loved ones, cheers ♥
Theme adapted from orderedlist
Multicore Locking Design & A Partial List of Lock Implementations
31 May 2021 - Guanzhou Hu
Concurrency plays a significant role in modern multi-core operating systems. We want a locking mechanism that is efficient (low latency), scalable (increasing the number of threads does not degrade performance too badly), and fair (considers the order of acquirement and does not make any one thread wait too long). This post summarizes a bit on hardware atomic instructions which modern locks are built upon, a comparison between spinning and blocking locks, and a partial list of representative lock implementations.
Mutual Exclusion & Locking
Let’s assume that the shared resource is a data structure on DRAM and that single-cacheline reads/writes to DRAM are atomic. Multiple running entities (say threads) run concurrently on multiple cores and share access to that data structure. The code for one access from one thread to the data structure is a critical section - a sequence of memory reads/writes and computations that must not be interrupted in the middle by other concurrent attempts of access. We want mutual exclusion: at any time, there will be at most one thread executing its critical section, and if some thread is doing that, other threads attempting to enter their critical section must wait. We do not want race conditions which may corrupt the data structure and yield incorrect results.
Based on this reasonable setup, it is possible to develop purely software-based algorithms. See this section of Wikipedia 1 for examples. Though very valuable in the theoretical aspect, these solutions are too sophisticated and quite inefficient to be deployed as locking primitives in an operating system under heavy load.
Modern operating systems, instead, rely on hardware atomic instructions – ISA supported instructions that are more than just single memory reads/writes, but are guaranteed by the hardware architecture to be atomic and unbreakable. The operating system implements (mutex) locks upon these instructions (in a threading library, for example). Threads have their critical sections protected in this way to get mutual exclusion:
lock.acquire();
... // critical section
lock.release();
Hardware Atomic Instructions
Here are three classic examples of hardware atomic instructions.
Test-and-Set (TAS)
The most basic hardware atomic instruction would be test-and-set (TAS). It writes a 1 to a memory location and returns the old boolean value on that location, atomically.
TEST_AND_SET(addr) -> old_val
// old_val = *addr;
// *addr = 1;
// return old_val;
Using this instruction, it is simple to build a basic spinlock that grants mutual exclusion (but not fairness and performance, of course).
void acquire() {
while (TEST_AND_SET(&flag) == 1) {}
}
void release() {
flag = 0;
}
Notice that this is a spinlock, which we will explain in the next section. Also, modern architectures have private levels of cache for each core. When threads are competing for the lock, there will be a great amount of cache invalidation traffic as they are all doing TEST_AND_SET to the same bit in the while loop.
Compare-and-Swap (CAS, Exchange)
Compare-and-swap (CAS, or Exchange) compares the value on a memory location with a given value, and if they are the same, writes a new value into it. It returns a boolean, which is the old value.
COMPARE_AND_SWAP(addr, val, new_val) -> old_val
// old_val = *addr;
// if (old_val == val)
// *addr = new_val;
// return old_val;
There are some variants of CAS such as compare-and-set or exchange, but their ideas are the same. It is also simple to build a basic spinlock out of CAS.
void acquire() {
while (COMPARE_AND_SWAP(&flag, 0, 1) == 1) {}
}
void release() {
flag = 0;
}
Load-Linked (LL) & Store-Conditional (SC)
Load-linked (LL) & store-conditional (SC) are a pair of atomic instructions used together. LL is just like a normal memory load. SC tries to store a value to the location and succeeds only if there’s no LL going on at the same time, otherwise returning failure.
LOAD_LINKED(addr) -> val
// return *addr;
STORE_CONDITIONAL(addr, val) -> success?
// if (no LL to addr happening) {
// *addr = val;
// return 1; // success
// } else
// return 0; // failed
Building a spinlock out of LL/SC:
void acquire() {
while (1) {
while (LOAD_LINKED(&flag) == 1) {}
if (STORE_CONDITIONAL(&flag, 1) == 1)
return;
}
}
void release() {
flag = 0;
}
Fetch-and-Add (FAA)
Fetch-and-add (FAA) is a less common atomic instruction that could be implemented upon CAS or just natively supported by the architecture. It operates on an integer counter.
FETCH_AND_ADD(addr) -> old_val
// old_val = *addr;
// *addr += 1;
// return old_val;
Spinning Lock vs. Blocking Lock
Before we list a few lock implementations, I’d like to give a comparison between spinning locks and blocking locks.
A spinning lock (or spinlock, non-blocking lock) is a lock implementation where lock waiters will spinning in a loop checking for some condition. The examples given above are basic spinlocks. Spinlocks are typically used for low-level critical sections that are short, small, but invoked very frequently, e.g., in device drivers.
- \(\uparrow\) Advantage: low latency for lock acquirement as there is no scheduling stuff kicking in – value changes reflect almost immediately;
- \(\downarrow\) Disadvantage:
- Spinning occupies the whole CPU core and wastes CPU power if the waiting time is long that could have been used for scheduling another free thread in to do useful work;
- Spinning also introduces the cache invalidation traffic throttling problem if not handled properly, as mentioned in the TAS section;
- Spinning locks make sense only if the scheduler is preemptive, otherwise there is no way to interrupt and break out of an infinite loop spin.
A blocking lock is a lock implementation where a lock waiter yields the core to the scheduler when the lock is currently taken. A lock waiter thread adds itself to the lock’s wait queue and blocks the execution of itself (called parking) to let some other free thread run on the core, until it gets woken up (typically by the previous lock holder) and scheduled back. It is designed for higher-level critical sections. The pros and cons are exactly the opposite of a spinlock.
- \(\uparrow\) Advantage: not occupying full core during the waiting period, good for long critical sections;
- \(\downarrow\) Disadvantage: switching back and forth from/to the scheduler and doing scheduling stuff takes significant time, so if the critical sections are fast and invoked frequently, better just do spinning.
It is possible to have smarter hybrid locks that combine spinning and blocking. This is now referred to as two-phase locking. POSIX mutex locks have the semantic option to first try to spin for a designed length of time. If the waiting time becomes too long, it switches to the scheduler to park. The Linux lock based on its futex syscall support 2 is a good example of such locks implementing the two-phase semantic.
Representative Lock Implementations
Here are a few interesting examples of lock implementations that appeared in the history of operating systems research. The list goes in the order from lower-level spinlocks to higher-level scheduling-based locks with more considerations.
Test-Test-and-Set (TTAS)
To ease the problem of cache invalidation in the simple TAS spinlock example, we could use a test-test-and-set (TTAS) protocol spinlock 3.
void acquire() {
do {
while (flag == 1) {}
} while (TEST_AND_SET(&flag) == 1);
}
void release() {
flag = 0;
}
The point is that, in the internal while loop, the value of flag will be cached in the core’s private cache and it is just spinning on a local cached copy. So most of the time, there won’t be cache throttling. Whenever the value of flag changes to 0 (lock seems released), cache invalidation traffic will invalidate the cached copy, terminating the internal while loop. Only then it falls back to an outer TEST_AND_SET check.
Ticket Lock
Ticket lock is a spinlock that uses the notion of “tickets” to improve arriving-order fairness.
volatile int ticket = 0;
volatile int turn = 0;
void acquire() {
int myturn = FETCH_AND_ADD(&ticket);
while (turn != myturn) {}
}
void release() {
turn++;
}
The downside is still the same cache throttling problem as in basic spinlocks.
A comparison table across Linux low-level spinlock implementations, including LL/SC and ABQL locks, can be found in this Wikipedia section 4.
Mellor-Crummey Scott (MCS)
MCS lock uses a linked-list structure to further optimize for the cache problem beyond TTAS. MCS is based on atomic swap. It queues the waiters into a linked-list and lets each waiter spin on its own node’s is_locked variable. A good demonstration of how this algorithm works can be found here 5.
MCS-TP (time-published) is an enhancement to MCS that involves a timestamp for letting a thread park after spinning for some time, as mentioned in the POSIX locks.
Remote Core Locking (RCL)
Lozi et al. proposed a lock delegation design that aims to improve the scalability of locks in this ATC’12 paper 6. Remote core locking recognizes the fact that, at any time, there will only be one thread executing the critical section, so why not let a dedicated “server” thread do that. For a critical section that is invoked frequently, RCL allocates a threads just for executing that critical section logic. Other threads use atomic cacheline operations to put themselves into a fixed mailbox-like queue, and the server thread loops over the queue serving them in order. This prevents the lock data structure from being cache-invalidated and transferred to different cores at different times.
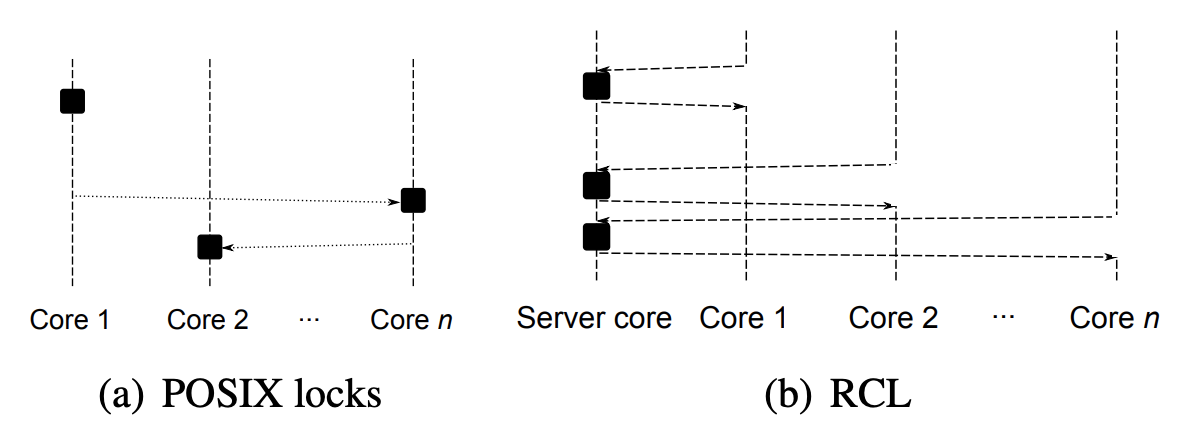
Figure 1 of the paper.
The downside is that it is harder to pass data/results out of the critical section. The server core will always be occupied and it can only be serving a chosen set of critical section logics.
Shuffle Lock (SHFL)
Kashyap et al. proposed an interesting enhancement called shuffling to blocking locks in this SOSP’19 paper 7. The shuffle locks are NUMA-aware: they take into consideration that on modern non-uniform memory access architectures, cores in the same NUMA socket (or in closer sockets) have faster access to local memory than to memory on a different socket (a “remote” socket). Hence, it would be a nice idea to reorder the wait queue of a lock dynamically depending on which NUMA socket is each waiter residing on.
Periodically, it assigns the first waiter in queue to be the shuffler, which traverses through the remaining wait queue and reorders it, grouping waiters on the same NUMA socket together. Then, there will be a higher chance that once a lock is released, the next holder scheduled will be on the same NUMA socket as the previous holder, so the transferring of lock data structures will be faster and there will be less cache invalidation traffic.
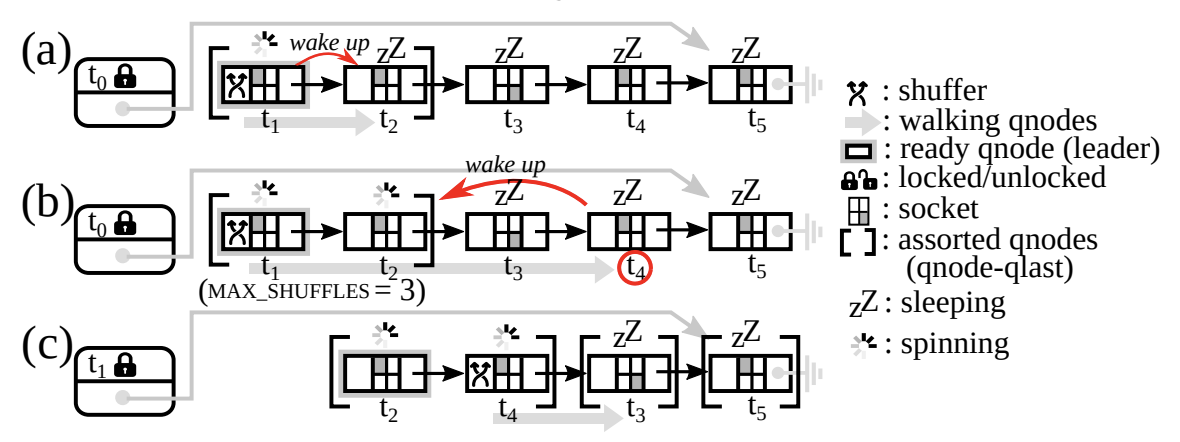
Figure 5 of the paper.
However, fairness in this case is not guaranteed as a lock waiter could possibly be pushed back in the queue constantly, which remains a big problem to be solved in shuffle locks.
References
Comments welcome! 😉