To all my loved ones, cheers ♥
Theme adapted from orderedlist
Brief Summary of Cache Modes & Cache Eviction Algorithms
07 Aug 2020 - Guanzhou Hu
Caching is an essential technique used broadly in computer system hierarchies. This post briefly summarizes existing cache mode configurations and cache eviction algorithms. This serves as a shallow review of cache systems before I go deeper into this field.
Cache Modes
Cache mode generally controls when to promote data into / flush data back from the cache. We can choose from one of the following cache mode configurations1:
- Write-Through: Reads promote data into cache; Writes write to cache and simultaneously “through” to backend storage.
- Only accelerates read operations
- Write-Back: Reads promote data into cache; Writes write to cache, marking the entries “dirty”, and then ACKs - dirty entries are flushed back to backend storage periodically, following a cleaning policy.
- Will improve performance of both read and write operations
- If the cache storage is volatile, there is a risk of data loss when the cache device fails with dirty entries within
- Cleaning policy adds in another dimension of complexity into the cache system
- Write-Around (Read-Only): Reads promote data into cache; Writes always write to backend storage, and also write to cache if & only if the entries are already mapped (by previous reads) in the cache.
- Only accelerates read operations
- Writes will not affect what data is mapped in cache, so it helps to avoid cache pollution where written data is actually not hot data
- Write-Invalidate: Reads promote data into cache; Writes write to backend storage and invalidates those entries in cache if they were mapped.
- Only accelerates read operations
- Progressively helps to avoid cache pollution, but may have a negative effect when most of the writes indeed write to hot data
- Write-Only: Reads do NOT promote data into cache; Writes perform exactly the same as Write-Back.
- Only accelerates write operations
- Also subject to data loss and extra complexity added by cleaning policy, just like Write-Back
Cache Eviction Algorithms
Eviction algorithm is an orthogonal aspect to cache mode. An eviction algorithm controls which entry in cache to evict back when a new entry is promoted and the cache is full. There has been a long path of research around this topic. I will briefly summarize all existing eviction algorithms I know, from the simplest FIFO to more optimized & complex ones2 3.
1) FIFO
Simple. Just keep a First-In-First-Out (FIFO) queue of all cache entries and evict the head of the queue.
Pure FIFO is very easy to implement but yields very poor cache performance under real-world scenarios.
2) Second-Chance
Second-Chance is an improvement to FIFO that accounts for time locality. It adds a reference bit to each entry of the FIFO queue.
- Whenever a cache line is referenced, it sets its corresponding queue entry’s reference bit as
1 - When evicting, it first looks at the head of the queue
- If its reference bit is not set, evict it
- Otherwise, clear its reference bit to
0and continue on the next entry in queue - If all entries originally have their reference bits set, then Second-Chance will loop back and effectively evict the head of the queue
3) CLOCK
CLOCK is a further implementation-level improvement to Second-Chance which eliminates the use of a FIFO queue. CLOCK keeps a circular list of cache lines called a clock, with a clock hand pointer pointing to the last examined entry in the list4.
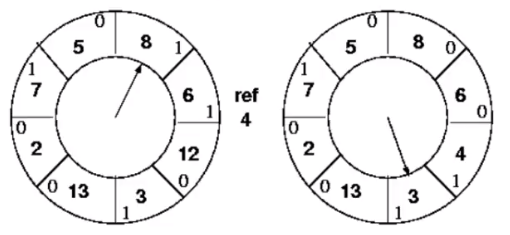
Figure from the this video.
- Whenever a cache line is referenced, it sets its corresponding list entry’s reference bit as
1 - When evicting, it first looks at the entry that the hand is pointing at
- If its reference bit is not set, choose to evict it and put the new incoming cache line data here
- Otherwise, clear its reference bit to
0and increment the hand pointer to point to the next entry in list - If all entries originally have their reference bits set, then CLOCK will loop back and effectively evict the entry originally pointed by the hand pointer
CLOCK acts exactly the same as Second-Chance. It is more efficient than Second-Chance since there is no dynamic FIFO queue here - it uses a fixed circular list instead.
CLOCK was introduced by Fernando Corbato at the 1960s.
4) LRU, Segmented LRU
Least-Recently Used (LRU) keeps track of the most recent time each cache line was referenced, and evict the least-recently used one.
LRU can yield near-optimal cache performance in theory, but implementing an LRU scheme is rather expensive. The most primitive way is to use a linked list of all cache lines.
- Whenever a cache line is referenced, traverse through the linked list, locate the corresponding entry in list, and move it to the tail of the list
- When evicting, evict the head of the list
As you can see, every cache reference operation will now trigger a traverse over the linked list, resulting in significant overhead. Segmented LRU reduces this overhead by dividing the cache into smaller segments (probably by logical address space). It evicts the least-recently used cache line in the segment that the new incoming entry belongs to.
Each segment maintains its own LRU list, which will be much shorter than an LRU list of the whole cache. Thus, the overhead of a cache reference operation to traverse over the linked list will be less significant.
5) NFU, Aging
Not Frequently Used (NFU) keeps a reference counter for each cache line. For each time interval, all cache lines referenced during this interval will increment its counter by 1. At eviction, NFU evicts the cache line with the smallest counter value.
The main problem with NFU is that “it keeps track of the frequency of use without regard to the time span”2. To make it aware of the time span of use, the Aging algorithm gives a higher weight to recent references and a lower weight to older references.
- At each time tick, it divides the reference counter by 2 (i.e., shifting right by 1 bit)
- If an entry is referenced, it increments the counter by, e.g.,
0b10000000
Example of the counter value of one entry:
Counter
Time tick #0: 0b00000000
Time tick #1: referenced 0b10000000
Time tick #2: 0b01000000
Time tick #3: referenced 0b10100000
6) ARC, CAR
Adaptive Replacement Cache (ARC) is an advanced eviction algorithm that has better cache performance than LRU and NFU. It keeps track of BOTH frequently used and recently used cache lines. This Wikipedia page gives a good demonstration of how this algorithm works5 3.
Basically, it splits the cache into two queues: T1 for recently used entries and T2 for frequently used entries (referenced at least twice). It also attaches two ghost queues B1 and B2 to the bottom of T1 and T2 to remember the metadata of recently evicted entries from those queues.
out <-[ B1 <-[ T1 <-!-> T2 ]-> B2 ]-> out
[ . . . . [ . . . . . . ! . .^. . . . ] . . . . ]
[ fixed cache size (c) ]
This text-based representation is from the above mentioned Wikipedia page5.
- The
!marker indicates the entering point of the cache- When a new entry arrives, it enters
T1to the left of! - Any entry in
T1orB1that gets referenced once more will be pushed intoT2to the right of! - Any entry in
T2ofB2, if referenced once more, will be re-pushed to the head ofT2to the right of!. This can repeat indefinitely
- When a new entry arrives, it enters
- The
^marker indicates the boundary of the two queuesT1andT2and is also the adaptive target position of!- It is initially at the same position as
! - A hit in
B1will increase the size ofT1, pushing^to the right. The bottom entry ofT2will be evicted toB2 - A hit in
B2will shrink the size ofT1, pushing^to the left. The bottom entry ofT1will be evicted toB1
- It is initially at the same position as
- New entry (re-)entering the cache will move
!towards^, evicting a corresponding entry on that side- Thus, the relative position of
!and^controls which queue to evict an item from - Thus, the name - “adaptive replacement”
- Thus, the relative position of
IBM holds a patent for the ARC algorithm.
CLOCK with Adaptive Replacement (CAR) is an implementation-level improvement to ARC which replaces the two queues T1 and T2 with two clocks.
7) LIRS, CLOCK-Pro
Low Inter-reference Recency Set (LIRS) is another advanced eviction algorithm that has better cache performance than LRU. It uses the concepts of reuse distance and recency to dynamically rank cache lines’ locality, and uses these metrics to decide which cache line to evict. This Wikipedia page gives a good demonstration of how this algorithm works3 6 7.
The reuse distance of a cache line is defined as the number of distinct cache lines accessed between the last two references of the cache line. (If a cache line is only referenced once, its reuse distance is \(\infty\).) The recency of a cache line is defined as the number of distinct cache lines accessed after the most recent reference of the cache line.
The cache is divided into two partitions: a Low Inter-reference Recency (LIR) partition which forms most of the cache and a High Inter-reference Recency (HIR) partition. All LIR entries are resident in the cache, while only some of the HIR entries are resident. All recently-referenced cache lines are placed in a FIFO queue called the LIRS stack S. Resident HIR entries are also placed in a FIFO queue called the stack Q.
Calling them “stacks” can be rather misleading - they are simply two queues.
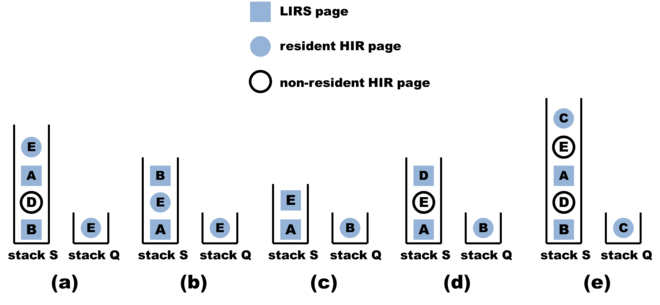
This figure from the above mentioned Wikipedia page6 demonstrates the status of the two queues S and Q:
- Accessing
B@ (a) \(\rightarrow\) goes to (b)- Accessing an entry will bring it to the top of
S, and all HIR entries at the bottom ofSwill be removed - This operation accounts for recency
- Accessing an entry will bring it to the top of
- Accessing
E@ (a) \(\rightarrow\) goes to (c):- Accessing an HIR entry will turn it into an LIR entry and bring it to the top of
S - The current bottom LIR entry of
Sturns back to an HIR entry and moves to the top ofQ - This operation accounts for reuse distance
- Accessing an HIR entry will turn it into an LIR entry and bring it to the top of
- Accessing
D@ (a) \(\rightarrow\) goes to (d), and accessingC@ (a) \(\rightarrow\) goes to (e)- At cache miss and eviction, the bottom resident HIR entry of
Qwill be evicted - This means evicting the entry with lowest inter-reference recency
- At cache miss and eviction, the bottom resident HIR entry of
CLOCK-Pro is an implementation-level improvement and an approximation to LIRS. It replaces the two queues S and Q with two clocks.
8) 2Q, MQ, CLOCK-2Q
Multi Queue (MQ) algorithms maintain 2 or more LRU queues, each representing a different lifetime length defined by the algorithm dynamically. Say we use \(m\) LRU queues. \(Q_{m-1}\) represents the shortest lifetime \(l_{m-1}\) and \(Q_0\) represents the longest lifetime \(l_0\). Each entry in the queues also keeps an access count (frequency).
- If a cache line in \(Q_i\) is not referenced for \(l_{m-1}\), it is demoted to \(Q_{i-1}\)
- If it is in \(Q_0\), it will be evicted
- If a cache line in \(Q_i\) is accessed more than \(2^i\) times, it is promoted to \(Q_{i+1}\)
There will also be a ghost list \(Q_{out}\) holding recently-evicted entries’ access counts.
- When a new entry comes in, query \(Q_{out}\)
- If \(Q_{out}\) has the access count \(f\) for this key, push the new entry to LRU queue \(Q_j\) where \(j = log_2(f)\)
- Otherwise, just push to \(Q_0\)
CLOCK-2Q is an implementation-level improvement and an approximation to 2Q algorithm, by replacing the LRU queues with clocks.
9) Random
Of course, you can simply adopt random eviction. Random eviction is very efficient and it actually has a rather good cache performance, considering that many of the complicated real-world workloads do not actually have a high degree of locality.
ARM processors use random eviction to enable a very efficient cache implementation.
这些 cache eviction algorithms 里面,LIRS、CLOCK-Pro、MQ、CLOCK-2Q 等都是华人学者在做的工作,包括 Song Jiang、Yuanyuan Zhou、Wengang Wang 等,或许是个值得注意的现象。
References
Comments welcome! 😉