To all my loved ones, cheers ♥
Theme adapted from orderedlist
Serializable Distributed Transactions over Sharded Scenario
31 May 2020 - Guanzhou Hu
Sharding is a common distributed system design to scale out and achieve better performance. Distributed transactions (concurrency control + atomic commits) are used to coordinate sharded nodes. It is important to implement serializable distributed transactions for such a system to act correctly.
Sharding & Distributed Transactions
Consider a classic key-value store scenario. Sharding represents the practice of partitioning data (key-value pairs) into multiple parts and put different parts on different nodes. Unlike replication which is for fault-tolerance, sharding is for performance & scalability - more nodes bring larger capacity and better load sharing.
A transaction is a sequence of read/write operations (records) carried out by a client to finish some task, e.g.:
# Transfer $1 from Y's bank account to X's.
read x;
read y;
set x = x + 1;
set y = y - 1;
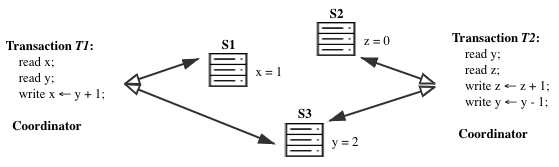
When data is sharded (which is often the case in real-world scenario), x and y are probably on different nodes of the database system. A transaction becomes a distributed transaction when the keys involved are distributed across different sharded nodes.
The “ACID” Principle & Serializability
An ideal database should satisfy the “ACID” principle1.
- Atomic: either the whole transaction is done or the whole transaction aborts, NO partial commit;
- Consistent: does not violate application-specific rules (e.g., bank balance cannot go below zero);
- Isolated \(\equiv\) Serializable: when there are multiple concurrent transactions, they do not interfere with each other;
- Formally, each transaction should not read partial results of other transactions
- Equivalently, this implies serializability as defined below
- Durable: once written, value should be persistently stored.
Serializability describes a history of multiple concurrent distributed transactions which has an order that, when executed one-by-one serially as if on a single machine, yields the same result. This is essentially the same requirement as the Isolation requirement in “ACID”.
To provide ACID distributed transactions, a distributed system must solve the following two questions at the same time:
- Concurrency control: how to prevent data race and coordinate among concurrent transactions?
- Atomic commit: how to ensure all-or-none commit (Atomic requirement in “ACID”)?
1. Pessimistic/Optimistic Concurrency Control
Concurrency control typically take two different forms - pessimistic/optimistic.
- Pessimistic concurrency control (PCC): use locking.
- Simple locking: when a transaction involves variables
x,y, &z, it first locks them on server nodes, then perform the actual transaction, then releases the locks. - An optimization is two-phase locking (2PL): acquire a key’s lock right before the first record of that key, instead of all at the beginning of transaction; Release of locks still need to be after the whole transaction finishes (or aborts).
- Faster when concurrency and conflicts are frequent ✓
- Simple locking: when a transaction involves variables
- Optimistic concurrency control (OCC): check serializability at commit time.
- Often needs locking mark + version numbers: if at commit time, some other transactions are processing the same variables, or some variables have newer versions than when I read them, then abort.
- Faster when concurrency and conflicts are rare ✓
Examples of optimistic concurrency control include Microsoft FaRM system2 which explores OCC over RDMA direct read and writes.
2. Atomic Commit with Two-Phase Commit (2PC)
Atomic commit is typically implemented by using two-phase commit (2PC)3. This is so common that I would put a link to its wikipedia page instead of rephrasing its definition here again: READ.
Several points worth noticing about 2PC:
- In distributed transactions, we often assume a coordinator for each transaction. In practice, the coordinator can be either the client itself who starts this transaction, or an interface node of the system, or even one of the sharded server nodes as a virtual coordinator.
- 2PC is widely criticized for its poor performance - a single participant/coordinator failure will block all the participants and the coordinator, thus make the system unavailable. Three-phase commit (3PC) can keep the system available when the coordinator crashes but cannot tolerate network-partitioning, thus not very interesting.
- Notice what states should be persisted and what messages should be retried during the 2PC process!
To improve the performance and throughput of such a system, we often want to avoid 2PC when it is not necessary. One way to do this is to distinguish between read-only transactions (RO) and read-write transactions (RW). RO transactions can bypass 2PC by using snapshot isolation: keep a multi-version DB with multiple timestamped versions of values for each key. Also assign a timestamp for each transaction. Then, the transaction only reads the newest versions not greater then its timestamp.
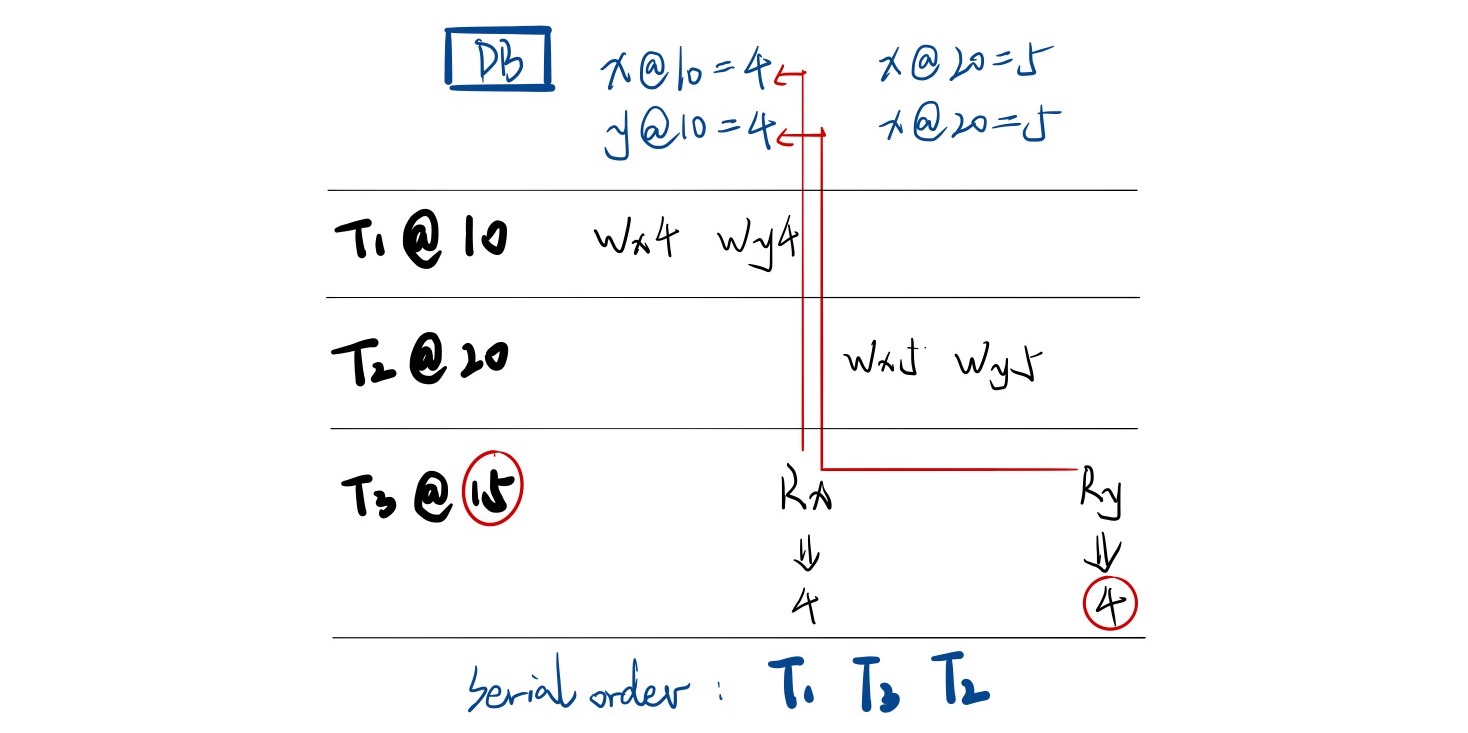
How to keep timestamps on all nodes synchronized now becomes a significant problem. Examples of snapshot isolation implementation include Google Spanner DB4 which introduces a novel TrueTime API.
Another way to enhance 2PC is to replicate each participant over multiple replicas that form a logical participant. In this way, each participant is very unlikely to fail, thus 2PC is very unlikely to block. Google Spanner DB does this over Paxos.
References
Comments welcome! 😉